
Some notes about working with AI Art
I’ve spent a fair amount of time in the last few days playing around with AI-generated art. I have a few mostly unorganized thoughts I wanted to get down, so here you go.
Ethics

I call this one “Hogan’s Heroes.” This was a rapidly made piece created to respond to a work conversation.
The ethical concerns of AI art are somewhat beyond me. I understand that a lot of artists feel like their art has been “stolen” by these companies for profit and without permission, but when you make your art publicly available, it tends to get appropriated and re-used in ways you didn’t anticipate.
Record labels, movie producers, and people who suddenly become memes without anyone asking them understand that all too well.
Somewhat related is the idea that this makes art “too easy.” This is an old argument about art and technology. In my lifetime I’ve seen it applied to Photoshop, 3D computer animation, VFX, and synthesizers. But historically it has also been lobbed at the art of photography itself. Here is Charles Baudelaire in 1859:
As the photographic industry was the refuge of every would-be painter, every painter too ill-endowed or too lazy to complete his studies, this universal infatuation bore not only the mark of a blindness, an imbecility, but had also the air of a vengeance… I am convinced that the ill-applied developments of photography, like all other purely material developments of progress, have contributed much to the impoverishment of the French artistic genius, which is already so scarce.
Photography is a deep, complex, and rich form of art, and it only continues to expand. Especially with the advent of the iPhone, which has led to a lot of amateur photographers dabbling as well.
Oh, here. Listen to photographer Antonio Olmos in 2013:
Photographers are getting destroyed by the rise of iPhones. The photographers who used to make £1,000 for a weekend taking wedding pictures are the ones facing the squeeze. Increasingly we don’t need photographers – we can do just as well ourselves.
The assumption that AI is really simple is unfounded, however. It is true that I can spend multiple days learning how to use an AI art tool and turn out results it would take years of practice to achieve. But it still requires a significant outlay of effort.
In my case, the effort is minimized a bit by my long experience programming computers. There’s still years of experience in the back there, it’s just in a different discipline.
It also becomes dramatically more difficult to use AI when you want to accomplish something specific. No doubt these tools will get easier, but… they have a long way to go.
So, speaking of, let me talk about some of the tools I’ve been using.
AI Tools
The AI art tools come in two basic varieties. You have those hosted by companies like Google, Microsoft, and OpenAI. You pay to use them by the minute or by the image. Furthermore, most of these AI tools work under community guidelines that dictate what content is acceptable.
Of course, deciding what is acceptable is often managed by program heuristics of some sort and there are often false positives. I’ve tripped over them a couple of times and can’t for the life of me understand why.
Midjourney

One of the things Midjourney can do is accept an image as guidance along with a prompt. This is where I got into trouble. I wanted to duplicate this pose in my prompt, but Midjourney told me the image was inappropriate.
Midjourney is an AI art tool that you work with using Discord. You write prompts into the chat room and a chatbot moderates between you and the Midjourney software. You can get really amazing results out of this pretty quickly, but once you start trying to nail something specific down things get difficult — and potentially expensive. Midjourney, like a lot of AI art machines, still has difficulty managing the number of limbs and a reasonable range of human motion.
Getting something usable out of the tool often means making many, many renders until you find one that’s acceptable. Then you can upscale the result (a little bit), which is typically when you realize your model has seven fingers or maybe an extra foot growing out of her knee.
It seems unlikely this is going to improve much with the existing approach. The way these tools typically work is to take a image full of random pixels and, over several iterations, remove everything that doesn’t look like the prompt.

The prompt for this was “1950s airbrush painting of a cheerful nun reclining on the beach, facing the viewer, sunny day, in the style of Antonio Vargas —no umbrella —aspect 16:9” Midjourney is trying, but…
Stable Diffusion
Stable Diffusion is a free AI art tool. There’s a large and community — maybe it’s better to say “multiple communities” that have sprung up around SD. In the spirit of open source code, these folks are expanding the tool set by training and creating their own models, tutorials, and other bits and bobs. There are several hosted options available, but you can also download and run on your own machine… maybe.
If you are a PC gamer you are probably set. If what you have is more of a business machine or one of the lower-end Macbook Pros, you are going to be waiting a long time. This is a problem because, just like Midjourney, you’re likely to be going through multiple iterations.
There are multiple front-end interfaces for SD. There’s an official SD one, of course, but there are two others that are pretty common. Automatic1111 is a common tool. Firing it up is a little like walking into the cockpit of a 747. There are knobs and controls everywhere, with little in the way of help. I spent a fair amount of time trying to use this tool and got some reasonable results out of it, but then I moved to ComfyUI.
If Automatic1111 looks like a jet cockpit, ComfyUI resembles nothing so much as a modular synth. Synthesizers make things too easy, remember. You add blocks which represent parts of the AI construction process — load the model, prep the decoder, run the sampler, view the results — and wire them all together in the order you want. Once you get the hang of it, it’s really handy. But setting up even a simple workflow is a bit of a shock, especially if you’ve been led to believe all you have to do is write a prompt.
All I’ve been doing recently with SD is trying out different models (each model is trained on different data has its own style), writing prompts, trying to get rid of extra fingers, and attempting to upscale beyond the relatively tiny images SD makes at the start. I prefer the control. I also like the fact that no one is looking over my shoulder to see if I am doing anything wrong. (Was that polka-dotted dress really too racy?)

This looks really great if you don’t scrutinize it too much. There’s an impression of Celtic knotwork, but it’s incoherent as a real knot. I don’t know what’s up with the weapons, those are strange. But overall, I’m very pleased with this one.
Off to the right is an image I worked with for multiple hours over several days. My scruples say AI art belongs to the community, and so I should share my prompts any time I share the art.
Positive prompt: photo of a female celtic warrior, pale green eyes, looking left Negative prompt: hands, fingers, cropped head, smooth skin, (makeup)
If you look at a lot of other people’s Stable Diffusion prompts you will notice they are much more detailed in comparison. Part of the reason mine are so short is I am using a newer model which requires a little less guidance. Another reason is a lot of SD artists take a kitchen-sink approach — I am not convinced all their keywords do anything. I mean, even in this one our warrior is looking right, facing right. So much for “looking left.”
The positive prompt guides what SD will include. Note I said nothing about weapons or armor, but SD decided those were implied by “warrior.” The hair style, skin tone, and decorations are all probably implied by “celtic.”
Sometimes things are implied that you wouldn’t expect. The first prompt did not include eye color, so I had an entirely different background that was shades of brown. Asking for green eyes got me the green background as well.
Sometimes changing a prompt slightly has very slight results, and I was able to refine the image over multiple passes. But other times, small changes have bizarre side effects. For example, asking for no armor gave me a simple green tunic instead, but it also got me two noses. “Hands” and “fingers” are in the negative prompt because I got a lot of weird results — our warrior here would be holding a sword, but by the blade, not the hilt. Oh, and she would have seven fingers.
Once I got a smaller version of her growing out of her shoulder.
“Smooth skin” and “makeup” are included because this model has a bias towards polishing away skin imperfections and gussying up all the ladies otherwise. Incidentally, removing the makeup also changed the hair to that barely tamed tangle.
Here is a screenshot of the ComfyUI workflow I used to create this.
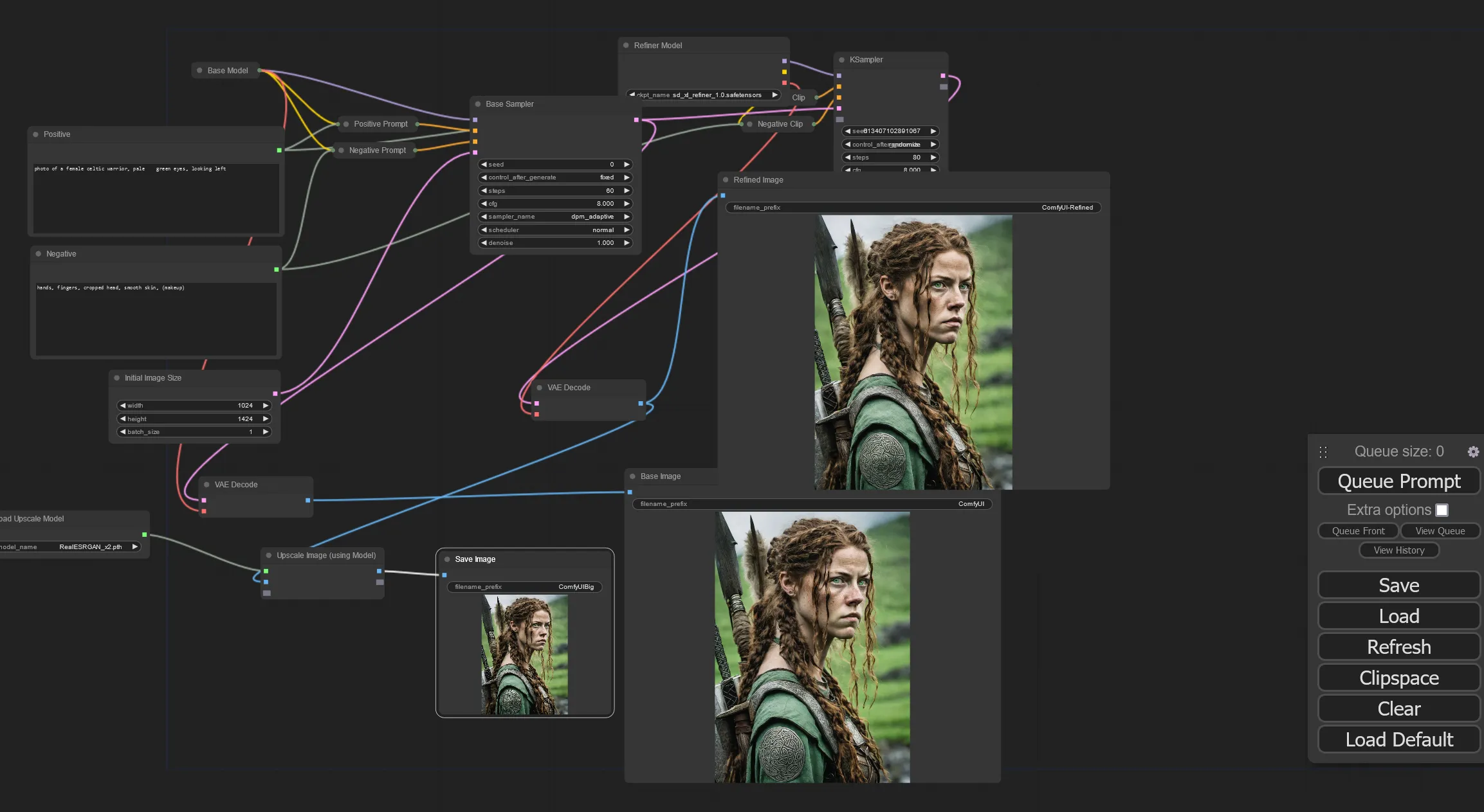
A workflow in ComfyUI.
This does not represent a complex workflow. Here’s what it’s doing:
- I am loading the SDXL base model
- Setting up the prompts, which need to be encoded specially for the model
- Setting up an empty image to use
- Feeding all these to the sampler (which combines the prompts and the model) and builds the image.
- The result of that (called the “latent image”) is fed to the image decoder to turn the latent image into an actual image, which is the middle result.
- It also sends the latent image to a second sampler, which uses a second model (SDXL refiner model) and it’s own encoded version of the prompts. This model improves the details created by the first.
- Then I decode that latent image so I can compare the results of this second step. (Sometimes things get worse.) That’s the far right image.
- Finally, I pass the decoded image data into a specialized sampler to double the image size. This uses a third model to upscale the image. Rather than just make it bigger, it fills in more details. That’s the lower left. It’s tiny because I just want to verify everything worked so I can save it.
Is this easier than grabbing a camera, contracting a model, getting the costume together? Actually, probably not, if you have a willing model who goes to Renaissance Festivals. But lacking those things, it’s not a bad substitute.
How I will use AI art
I do a fair amount of independent stuff. This blog as well as my movie blog over at FilmHydra. I do all of this without adding advertising or even tracking marketing data; it’s purely hobby. I would love to have more art in my posts, and this is a way to get it. Realistically, I am not going to buy stock photos or contract with an artist every time I need something.
I also forsee a day when it is very difficult to get screen shots from movies. Studios have already made it very difficult to get screen shots from streamed films. But those are central (and important) to my movie reviews — so maybe I will start replacing some of those with AI renditions of the scene. I think that would be fun. Again, I was never likely to contract an artist for those.
But mostly I will do this for my own entertainment, just as I have with almost all of the other art I’ve ever done. And this blog post. And all the rest.
But what about the artists?
Artists were already in a bad way before AI art came along. IPhones are limiting options for working photographers. The demise of Twitter has made it hard for other visual artists to reach their customers. Things have been rough for artists for a long time, and yes — this is another blow. Especially for artists uninterested in using these tools themselves.
The only real solution for this I can see is greater public investment in the arts, either directly through grants or indirectly through something like Universal Basic Income. My feeling is this. AI art is an interesting and entertaining tool with a lot of potential. Lots of people will make lots of bad art with it, but I make lots of bad art now with pencil and paper. It’s fine.
But artists have been continually squeezed in the service of wringing more productive time out of people to fill the 1%’s silos of cache. This is not a technology problem, it’s a political priority problem.
That’s my feeling anyway. I don’t get to make these decisions, but anytime anyone asks for my opinion — in person or in the voting booth — that’s what it is.
We should pay people to make art. Lots of art. Any way they want to do it. It’s a public good.